Модуль распознавания голоса
Приветствую вас, дорогие друзья. Наконец-то я добрался до записи урока по работе с голосовым модулем. Вижу вам понравилась моя самоделка с голосовым управлением и многие уже начали интересоваться, когда же выйдет практический урок по работе с модулем голосового управления.

О плюсах данного модуля распознавания:
— Модуль автономный и может работать без внешнего управляющего контроллера, что очень важно для радиолюбителей не знакомых с программированием.
— На ряду с другими моделями данный модуль выгодно отличается функциональностью, ценой и относительной простотой в управлении и подключении.
— Имеет высокую распознавающую способность.
— Никакого смартфона не требуется.
И так поехали! Данное видео будет направлено в первую очередь на новичков, тех, кто не знаком с программирование и интерфейсами, в общем для обычных радио любителей. В видео я покажу всё от «А» до «Я»: начнем с установки программ и подключения и закончим конкретным результатом автономной работы модуля.
Начнем же мы все равно с теоретических знаний, дабы понимать, как же все-таки работает это чудо инженерной мысли. Перво-наперво вам нужно знать некоторые характеристики данного модуля распознавания голоса:
Потребляемый ток: не более 40 мА, ток не критичный, так что просто учтите. Напряжение питания – 5 В, мы будем питать модуль USB порта компьютера при программировании, а дальше при работе вы сами решите от чего запитывать. Точность распознавания голосовой команды – 99% при идеальных условиях. Модуль распознавания голоса версии V3.1 способен запомнить 80 голосовых команд! Что на мой взгляд вполне достаточно для любых целей. Но опять же это «НО». Но модуль в единицу времени может распознавать только семь любых команд, а каких сень команд – выбирать вам.
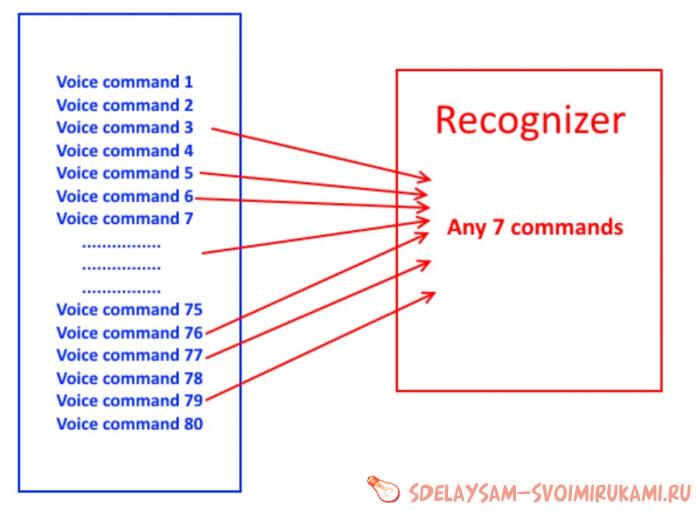
То есть, вы можете записать в базу все 80 команд, но для распознавания выбрать только семь, любых семь из восьмидесяти. Это как с компьютером: на жестки диск можно записать 80 команд, а в оперативной памяти работать только с 7-ю командами. Если вам трудно это сейчас понять, то чуть позже на практике, я думаю, вам станет ясно о чём идет речь. Длинна голосовой команды – 1,5 секунды (1500мс) максимальное значение. Управлять платой модуля можно по интерфейсу UART, а вот снимать информацию можно как UART, так с портов GPIO, расположенных на плате. Собственно говоря, чем мы и займемся: будем снимать сигнал с выхода порта.
Переходим к практической части.
Что же нам понадобиться для работы?
— Сам модуль распознавания голоса версии V3 (V3.1) Версия не так важна – принцип работы у всех одинаков. Модуль идет с микрофоном.
— Руководство по модулю, то есть дата шит.
— Преобразователь интерфейсам USB-UART.
Все ссылки на покупку и скачивание софта под видео, в конце статьи.
Вот и всё. Как говорил Гагарин – «Поехали».
Скачиваем руководство и терминал. Терминал устанавливаем. Подключаем модуль к преобразователю интерфейса.
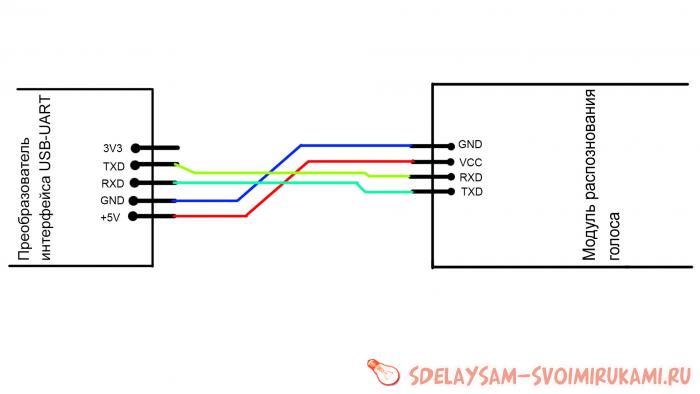
Будьте очень внимательны при подключении. Не страшно, если вы перепутаете TXD и RXD, ничего страшного не произойдёт. А вот если вы перепутаете плюс питания с общим проводом – это будет катастрофа! Как случилось у меня – сразу сгорел модуль и порт компьютера! Будьте очень внимательны и не повторяйте моих ошибок. Не суетитесь, не спешите, проверьте цепь несколько раз перед включением, и только после этого подключайте к USB.
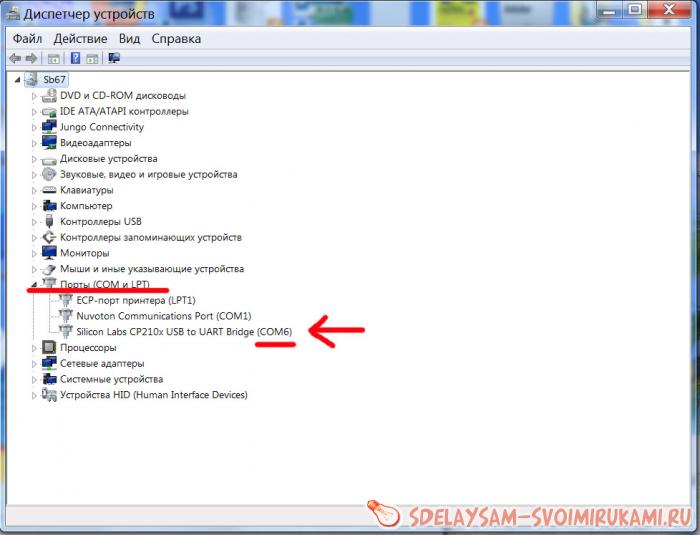
После подключения к USB ваша система начнет поиск драйверов к преобразователю, в 90% случаев система сама находит драйвер и устанавливает его, но если этого по каким-то причинам не произошло, то вам буден нужно самим найти драйвер в сети и установить его. Для этого в поисковой строке напишите «CP2102 драйвер скачать» или типа того, модуль распространенный, вариантов драйверов полно.
Далее, после успешной установки оборудования идем в диспетчер устройств и смотрим порты. Нас интересует присвоенный номер нашего преобразователя. Когда узнали номер порта запускаем терминал. Идем в настройки и устанавливаем значения как у меня на рисунке.
Пишем в окне терминала команду – «AA 02 00 0A» (из даташита | AA | 02 | 00 | 0A |). Во всех командах всегда буквы заглавные и латинские.
Поле отправки вам должен последовать ответ, типа: «AA 08 00 STA BR IOM IOPW AL GRP 0A» (или из даташита | AA | 08 | 00 | STA | BR | IOM | IOPW | AL | GRP | 0A |). Если ответ пришел, то все отлично, пол дела сделано. Если нет, играемся с настройками настройками скорости передачи в терминале, просто возможно модуль настроен на другую скорость.
Я не буду останавливаться на том что означает данный ответ модуля, это вы сами сможете посмотреть в инструкции. А команда — это запрос установленных настроек.
Теперь необходимо подключить нагрузку к модулю. В роле нагрузки я буду использовать светодиоды с резисторами. Ну в дальнейшем, при эксплуатации эти светодиоды будут заменены на реле управления нагрузкой с транзисторными ключами, думаю это понятно.
Поясню саму команду «AA 02 00 0A» — это пакет состоящий из 4 байт, байты — это попарные символы в шестнадцатеричной системе – AA,02,00,0A. Во всех командах пакет будет начинаться байтом AA и заканчиваться байтом 0A (Ноль и A) – это обязательное условие. Ответы модуля будут так же начинаться и заканчиваться этими символами.
«AA 02 00 0A» — второй байт этой команды означает количество байт между байтами начала и конца, короче кроме AA и 0A. А все что между ними считаем и пишем во второй байт. Как видим в этом примере, что между AA и 0A стоят два байта — 02 00, следовательно – 02, то есть число считает само себя. Еще пример, «AA 03 20 01 0A» то есть между AA и 0A стоят три байта — «03 20 01», следовательно, второй байт – 03. Думаю, Вам будет понятно.
Команда «12» — настройка портов модуля.
На плате модуля расположены порты, с которых мы будем снимать сигнал, прежде чем это делать, необходимо настроить эти порты. Настроить порты можно это командой
«AA 03 12 01 0A» — третий байт — это команда, а четвертый значение команды. Четвертый байт может принимать следующие значения и задавать следующие опции: если «00» — режим импульса, то есть при распознавании голосовой команды, на нужный нам порт подается короткий импульс. Если «01» — режим инверсии, то есть при распознавании голосовой команды, на нужный нам порт сменит состояние на противоположное, если был 0 – станет 1 и наоборот. Если «02» — режим при котором порт переходит в ноль. Если «03» — режим при котором порт переходит в единицу.
Команда «20» — настройка портов модуля.
«AA 03 20 01 0A» — третий байт — это номер команды, которую мы будем записывать. Пример записи двух команд 1 и 2: «AA 04 20 01 02 0A». Пример записи двух команд 1, 2, 3: «AA 05 20 01 02 03 0A».
Команда «30» — загрузка записи в «распознаватель» модуля.
«AA 03 30 01 0A» — третий байт команда загрузки в память распознавателя записи 01. Если нужно записать две команды — «AA 04 30 01 02 0A», если нужно записать все семь команд — «AA 09 30 01 02 03 04 05 06 07 0A».
Команда «15» — Автозагрузка голосовых команд в распознаватель при включении питания – автономный режим работы без внешнего контроллера.
«AA 03 15 07 01 02 03 0A» — третий байт команда, четвертый байт метка команд, то есть своеобразный идентификатор, и равен 01 для загрузки одной команды, 03 – для загрузки двух команд, 07 – для загрузки трех команд и так далее, смотрите в даташит таблицу. Ну а дальше идут номера команд, которые нужно загружать.
Вот и всё: проверили связь с модулем, сконфигурировали порты, записали команды, настроили автозагрузки голосовых команд.
Об остальных командах читайте в даташит. Я лишь объяснил примерный вид работы с модулем.
Источник
Пишем голосового ассистента на Python
Введение
Технологии в области машинного обучения за последний год развиваются с потрясающей скоростью. Всё больше компаний делятся своими наработками, тем самым открывая новые возможности для создания умных цифровых помощников.
В рамках данной статьи я хочу поделиться своим опытом реализации голосового ассистента и предложить вам несколько идей для того, чтобы сделать его ещё умнее и полезнее.

Что умеет мой голосовой ассистент?
| Описание умения | Работа в offline-режиме | Требуемые зависимости |
| Распознавать и синтезировать речь | Поддерживается | pip install PyAudio (использование микрофона) |
pip install pyttsx3 (синтез речи)
Для распознавания речи можно выбрать одну или взять обе:
- pip install SpeechRecognition (высокое качество online-распознавания, множество языков)
- pip install vosk (высокое качество offline-распознавания, меньше языков)
Шаг 1. Обработка голосового ввода
Начнём с того, что научимся обрабатывать голосовой ввод. Нам потребуется микрофон и пара установленных библиотек: PyAudio и SpeechRecognition.
Подготовим основные инструменты для распознавания речи:
Теперь создадим функцию для записи и распознавания речи. Для онлайн-распознавания нам потребуется Google, поскольку он имеет высокое качество распознавания на большом количестве языков.
А что делать, если нет доступа в Интернет? Можно воспользоваться решениями для offline-распознавания. Мне лично безумно понравился проект Vosk.
На самом деле, необязательно внедрять offline-вариант, если он вам не нужен. Мне просто хотелось показать оба способа в рамках статьи, а вы уже выбирайте, исходя из своих требований к системе (например, по количеству доступных языков распознавания бесспорно лидирует Google).
Теперь, внедрив offline-решение и добавив в проект нужные языковые модели, при отсутствии доступа к сети у нас автоматически будет выполняться переключение на offline-распознавание.
Замечу, что для того, чтобы не нужно было два раза повторять одну и ту же фразу, я решила записывать аудио с микрофона во временный wav-файл, который будет удаляться после каждого распознавания.
Таким образом, полученный код выглядит следующим образом:
Возможно, вы спросите «А зачем поддерживать offline-возможности?»
Я считаю, что всегда стоит учитывать, что пользователь может быть отрезан от сети. В таком случае, голосовой ассистент всё еще может быть полезным, если использовать его как разговорного бота или для решения ряда простых задач, например, посчитать что-то, порекомендовать фильм, помочь сделать выбор кухни, сыграть в игру и т.д.
Шаг 2. Конфигурация голосового ассистента
Поскольку наш голосовой ассистент может иметь пол, язык речи, ну и по классике, имя, то давайте выделим под эти данные отдельный класс, с которым будем работать в дальнейшем.
Для того, чтобы задать нашему ассистенту голос, мы воспользуемся библиотекой для offline-синтеза речи pyttsx3. Она автоматически найдет голоса, доступные для синтеза на нашем компьютере в зависимости от настроек операционной системы (поэтому, возможно, что у вас могут быть доступны другие голоса и вам нужны будут другие индексы).
Также добавим в в main-функцию инициализацию синтеза речи и отдельную функцию для её проигрывания. Чтобы убедиться, что всё работает, сделаем небольшую проверку на то, что пользователь с нами поздоровался, и выдадим ему обратное приветствие от ассистента:
На самом деле, здесь бы хотелось самостоятельно научиться писать синтезатор речи, однако моих знаний здесь не будет достаточно. Если вы можете подсказать хорошую литературу, курс или интересное документированное решение, которое поможет разобраться в этой теме глубоко — пожалуйста, напишите в комментариях.
Шаг 3. Обработка команд
Теперь, когда мы «научились» распознавать и синтезировать речь с помощью просто божественных разработок наших коллег, можно начать изобретать свой велосипед для обработки речевых команд пользователя 😀
В моём случае я использую мультиязычные варианты хранения команд, поскольку у меня в демонстрационном проекте не так много событий, и меня устраивает точность определения той или иной команды. Однако, для больших проектов я рекомендую разделить конфигурации по языкам.
Для хранения команд я могу предложить два способа.
1 способ
Можно использовать прекрасный JSON-подобный объект, в котором хранить намерения, сценарии развития, ответы при неудавшихся попытках (такие часто используются для чат-ботов). Выглядит это примерно вот так:
Такой вариант подойдёт тем, кто хочет натренировать ассистента на то, чтобы он отвечал на сложные фразы. Более того, здесь можно применить NLU-подход и создать возможность предугадывать намерение пользователя, сверяя их с теми, что уже есть в конфигурации.
Подробно этот способ мы его рассмотрим на 5 шаге данной статьи. А пока обращу ваше внимание на более простой вариант
2 способ
Можно взять упрощенный словарь, у которого в качестве ключей будет hashable-тип tuple (поскольку словари используют хэши для быстрого хранения и извлечения элементов), а в виде значений будут названия функций, которые будут выполняться. Для коротких команд подойдёт вот такой вариант:
Для его обработки нам потребуется дополнить код следующим образом:
В функции будут передаваться дополнительные аргументы, сказанные после командного слова. То есть, если сказать фразу «видео милые котики«, команда «видео» вызовет функцию search_for_video_on_youtube() с аргументом «милые котики» и выдаст вот такой результат:

Пример такой функции с обработкой входящих аргументов:
Ну вот и всё! Основной функционал бота готов. Далее вы можете до бесконечности улучшать его различными способами. Моя реализация с подробными комментариями доступна на моём GitHub.
Ниже мы рассмотрим ряд улучшений, чтобы сделать нашего ассистента ещё умнее.
Шаг 4. Добавление мультиязычности
Чтобы научить нашего ассистента работать с несколькими языковыми моделями, будет удобнее всего организовать небольшой JSON-файл с простой структурой:
В моём случае я использую переключение между русским и английским языком, поскольку мне для этого доступны модели для распознавания речи и голоса для синтеза речи. Язык будет выбран в зависимости от языка речи самого голосового ассистента.
Для того, чтобы получать перевод мы можем создать отдельный класс с методом, который будет возвращать нам строку с переводом:
В main-функции до цикла объявим наш переводчик таким образом: translator = Translation()
Теперь при проигрывании речи ассистента мы сможем получить перевод следующим образом:
Как видно из примера выше, это работает даже для тех строк, которые требуют вставки дополнительных аргументов. Таким образом можно переводить «стандартные» наборы фраз для ваших ассистентов.
Шаг 5. Немного машинного обучения
А теперь вернёмся к характерному для большинства чат-ботов варианту с JSON-объектом для хранения команд из нескольких слов, о котором я упоминала в пункте 3. Он подойдёт для тех, кто не хочет использовать строгие команды и планирует расширить понимание намерений пользователя, используя NLU-методы.
Грубо говоря, в таком случае фразы «добрый день«, «добрый вечер» и «доброе утро» будут считаться равнозначными. Ассистент будет понимать, что во всех трёх случаях намерением пользователя было поприветствовать своего голосового помощника.
С помощью данного способа вы также сможете создать разговорного бота для чатов либо разговорный режим для вашего голосового ассистента (на случаи, когда вам нужен будет собеседник).
Для реализации такой возможности нам нужно будет добавить пару функций:
А также немного модифицировать main-функцию, добавив инициализацию переменных для подготовки модели и изменив цикл на версию, соответствующую новой конфигурации:
Однако, такой способ сложнее контролировать: он требует постоянной проверки того, что та или иная фраза всё ещё верно определяется системой как часть того или иного намерения. Поэтому данным способом стоит пользоваться с аккуратностью (либо экспериментировать с самой моделью).
Заключение
На этом мой небольшой туториал подошёл к концу.
Мне будет приятно, если вы поделитесь со мной в комментариях известными вам open-source решениями, которые можно внедрить в данный проект, а также вашими идеями касательно того, какие ещё online и offline-функции можно реализовать.
Документированные исходники моего голосового ассистента в двух вариантах можно найти здесь.
P.S: решение работает на Windows, Linux и MacOS с незначительными различиями при установке библиотек PyAudio и Google.
Кстати, тех, кто планирует строить карьеру в IT, я буду рада видеть на своём YouTube-канале IT DIVA. Там вы сможете найти видео по тому, как оформлять GitHub, проходить собеседования, получать повышение, справляться с профессиональным выгоранием, управлять разработкой и т.д.
Источник